7 лучших бесплатных программных решений с открытым исходным кодом для управления базами данных
Содержание:
- Инструкция CREATE SCHEMA
- Программа для кадрового агентства
- Модель данных “ключ-значение” и документная модель
- Резервное копирование — почему оно необходимо
- Примеры баз данных
- Разделение пользователей и схем
- Заключительные замечания об агрегатноориентированных базах данных
- Преимущества графовых баз данных
- Механизмы вычисления графов
- Базы данных и организация веб-ресурса
- Итоги
- Вас заинтересует / Intresting for you:
Инструкция CREATE SCHEMA
В примере ниже показано создание схемы и ее использование для управления безопасностью базы данных. Прежде чем выполнять этот пример, необходимо создать пользователей базы данных Alex и Vasya, как будет описано в следующей статье (вы можете вернуться к этим примерам позже).
В этом примере создается схема poco, содержащая таблицу Product и представление view_Product. Пользователь базы данных Vasya является принципалом уровня базы данных, а также владельцем схемы. (Владелец схемы указывается посредством параметра AUTHORIZATION. Принципал может быть владельцем других схем и не может использовать текущую схему в качестве схемы по умолчанию.)
Две другие инструкции, применяемые для работы с разрешениями для объектов базы данных, GRANT и DENY, подробно рассматриваются позже. В этом примере инструкция GRANT предоставляет инструкции SELECT разрешения для всех создаваемых в схеме объектов, тогда как инструкция DENY запрещает инструкции UPDATE разрешения для всех объектов схемы.
С помощью инструкции CREATE SCHEMA можно создать схему, сформировать содержащиеся в этой схеме таблицы и представления, а также предоставить, запретить или удалить разрешения на защищаемый объект. Как упоминалось ранее, защищаемые объекты — это ресурсы, доступ к которым регулируется системой авторизации SQL Server. Существует три основные области защищаемых объектов: сервер, база данных и схема, которые содержат другие защищаемые объекты, такие как регистрационные имена, пользователи базы данных, таблицы и хранимые процедуры.
Инструкция CREATE SCHEMA является атомарной. Иными словами, если в процессе выполнения этой инструкции происходит ошибка, не выполняется ни одна из содержащихся в ней подынструкций.
Порядок указания создаваемых в инструкции CREATE SCHEMA объектов базы данных может быть произвольным, с одним исключением: представление, которое ссылается на другое представление, должно быть указано после представления, на которое оно ссылается.
Принципалом уровня базы данных может быть пользователь базы данных, роль или роль приложения. (Роли и роли приложения рассматриваются в одной из следующих статей.) Принципал, указанный в предложении AUTHORIZATION инструкции CREATE SCHEMA, является владельцем всех объектов, созданных в этой схеме. Владение содержащихся в схеме объектов можно передавать любому принципалу уровня базы данных посредством инструкции ALTER AUTHORIZATION.
Для исполнения инструкции CREATE SCHEMA пользователь должен обладать правами базы данных CREATE SCHEMA. Кроме этого, для создания объектов, указанных в инструкции CREATE SCHEMA, пользователь должен иметь соответствующие разрешения CREATE.
Программа для кадрового агентства
Скачать пример базы данных288 Кб (XML)
Пример работы агентства по подбору персонала, содержащий базу работодателей и соискателей, историю обращений, а также проекты: размещение информации в СМИ и подбор персонала для двух предприятий. Демонстрационная база содержит дополнительные поля для заполнения анкеты соискателя, а также анкету для работодателя.Скачайте файл и запустите для разархивации. Получится два файла: demobase_rekrut.xml и scheme.new.xml. Установив демо-версию, скопируйте оба файла в папку с программой. Запустите программу. Выберите в меню пункт «Файл/Принять файл» и откройте файл demobase_rekrut.xml.
Модель данных “ключ-значение” и документная модель
Ранее мы говорили о том, что базы данных типа “ключ—значение” и документные базы данных являются сильно агрегатно-ориентированными. Мы имели в виду, что эти базы данных в основном были сконструированы из агрегатов. Базы данных обоих типов состоят из множества агрегатов, каждый из которых имеет ключ или идентификатор, который используется для доступа к данным.
Эти две модели отличаются друг от друга тем, что в базе данных “ключ- значение” агрегат является непроницаемым для базы данных — просто большой черный ящик, состоящий из преимущественно бессмысленных битов. В противоположность этому документная база может видеть структуру агрегата. Преимущество непрозрачности заключается в том, что в агрегате можно хранить все что угодно. База данных может ограничивать общий размер агрегата, но в остальном мы имеем полную свободу. Документная база данных накладывает ограничения на то, что можно хранить в агрегате, определяя допустимые структуры и типы. Однако за это мы получаем большую гибкость доступа. В хранилище типа “ключ-значение” мы можем просматривать агрегат только с помощью его ключа. В документной базе данных мы можем посылать базе данных запросы, касающиеся полей в агрегате, извлекать части агрегата, а не весь агрегат целиком, причем база данных может создавать индексы с учетом содержимого агрегата. На практике разделительная линия между базами данных типа “ключ-значение” и документными базами данных довольна расплывчата. Люди часто записывают идентификаторы в документные базы данных, чтобы выполнять поиск в стиле “ключ-значение”. Базы данных, классифицированные как базы типа “ключ-значение”, могут предлагать новые структуры для данных, помимо непрозрачных агрегатов. Например, база данных Riak позволяет добавлять метаданные к агрегатам для индексирования и установления связей между агрегатами, a Redis позволяет разбивать агрегаты на списки или множества. Кроме того, можно обеспечить механизм запросов с помощью интегрированных средств поиска, как в базе данных Solr. Например, поисковый механизм базы данных Riak, аналогичный поисковому механизму базы Solr, выполняет поиск агрегатов, хранящихся в виде структур JSON или XML.
Несмотря на такое нечеткое разделение, эти две категории в целом отличаются друг от друга. Базы данных типа “ключ—значение”, как правило, выполняют поиск агрегатов по ключу. В документных базах данных пользователь должен подать запрос, основанный на внутренней структуре документа; это может быть ключ, но, скорее всего, это будет нечто другое.
Резервное копирование — почему оно необходимо
Необходимо периодически создавать бэкапы — резервные копии сайта и базы данных. Обычно хостинги предоставляют услуги по созданию копий сайта.
- Чтобы “откатить” неудачные изменения на сайте и вернуться к предыдущей версии.
- Для восстановления веб-ресурса после вирусной атаки или взлома сайта.
- Для восстановления после сбоев.
Восстановить предыдущую версию можно с той даты, за которую сохранены база и конфигурация сайта. Легче периодически делать копии, чем восстанавливать портал с нуля.
От автора: Мы живем в век информации, поэтому людьми были разработаны достаточно удобные технологии для ее хранения. Сегодня я покажу вам, как создать базу данных на хостинге и зачем это вообще необходимо.
Я уже думаю, что вы и сами понимаете, для чего нужна БД – для хранения данных. При установке вручную любого движка от вас потребуется ее создание. Ну хорошо, а как же это сделать? Для этого есть как минимум 2 простых способа.
Создание БД через панель управления сервером
Пожалуй, это самый простой вариант. Любой хостинг предоставляет вам Cpanel или любую другую панель, чтобы управлять вашими сайтами. Там вы можете найти пункт “Базы данных”, где можно в визуальном режиме создать новую БД, нового пользователя, после чего связать его с базой. Пользователя создавать и не обязательно, если он уже создан. В качестве прав нужно установить все, если это администраторский профиль.
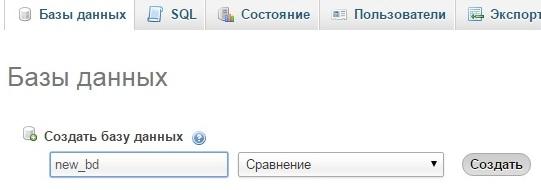
Создание базы данных на хостинге утилитой PhpMyAdmin
На самом деле утилит для работы с MySQL и другими БД много, но с этой встречаются чаще всего. Создать базу в phpmyadmin тоже легко.
JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
Нажимаем Базы данных и появится список баз, а также возможность добавить новую, вписав ее имя. После создания нужно будет также добавить или создать нового пользователя для БД. Для этого у новой базы отредактируйте привилегии.
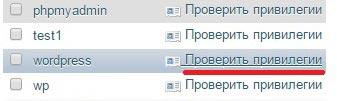
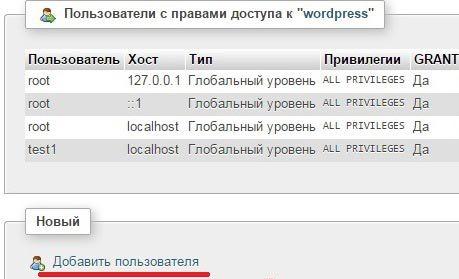
Как видите, тут можно посмотреть, какие пользователи уже имеют доступ к БД, а также добавить нового.
Перенос БД и ее загрузка на другой хостинг
Прежде всего, хочу скачать, что ваша БД – это вообще практически самое важное и ценное, чем вы обладаете. Ведь это все записи, страницы, отзывы, комментарии и все, что там еще может быть на сайте
И если это пропадет, то для вас это полная беда. Поэтому первым делом позаботьтесь о том, чтобы постоянно совершалось резервное копирование базы, причем желательно в несколько мест. Таким образом, вы защитите себя.
Если что, расширение дампа базы данных – sql. То есть на компьютер вы скачиваете именно дамп БД. Ну а как же, собственно, загрузить БД? Лучше всего для этого использовать всю ту же утилиту – PhpMyAdmin. Зайдем в нее. Там есть кнопка Импорт, но пока не трогаем его. Для начала нужно будет создать новую БД или удалить все таблицы в старой.
Короче, вам нужна чистая, голая БД. Выбираем ее и вот именно в нее импортируем наш дамп. Если все прошло успешно, вы увидите появляющиеся в БД таблицы, а со временем убедитесь в правильности своих действий, когда перейдете на сайт, для которого все эти манипуляции и совершались.
Интересно, что все это можно совершить и через панель управления сервером. Там тоже есть возможность закачивать дампы баз данных.
Как связать с сайтом?
Связка происходит автоматически на этапе установки движка. Там вы указываете имя БД, имя пользователя и его пароль для доступа к базе, сервер (почти всегда localhost) и префикс таблиц. Но если вдруг в процессе работы что-то меняется, то нужно будет изменить данные.
Например, вы поменяли имя базы или удалили пользователя и назначили другого. Соответственно, если вы не поменяете нужные параметры, при заходе на сайт будет отображаться ошибка соединения с БД и ни о какой работе ресурса нельзя будет даже говорить.
В связи с этим, СРАЗУ же после внесения подобных изменений нужно изменять и соответствующие параметры. Если у вас движок wordpress, то они хранятся в файле wp-config. В частности, там есть такие константы:
Если Вам нужна готовая база данных Access, то Вы пришли по адресу. Готовая база данных Access — это ряд преимуществ. Не надо ожидать срока выполнения заказа работы, готовая работа стоит значительно дешевле, чем написание ее «с нуля». Если так сложились обстоятельства, что зачетную или курсовую работу надо сдавать уже завтра? Лучшего выхода не найти, чем приобрести готовую работу. У нас имеется большая база готовых работ, выполненных за несколько лет нашей работы. Подберите себе готовую базу данных MS Access. Данный список продолжает пополняться.

Примеры баз данных
Для наглядной демонстрации работы программы советуем посмотреть примеры баз данных. Универсальность программы позволяет использовать «Инфокуб» в любых сферах деятельности, от фитнес-центра до рекламного агенства.
Сохраните файл и откройте его в «Инфокубе» через меню «Файл» → «Принять файл»
| Рекламное агентство665 Кб (XML) |
| Юридическое агентство555 Кб (XML) |
| Программа для сервисного центра93 Кб (XML) |
| Программа для туризма217 Кб (XML) |
| Программа для кадрового агентства288 Кб (XML) |
| Программа для деятельности по разливу и доставке питьевой воды252 Кб (XML) |
| Программа для агентства недвижимости91 Кб (XML) |
| Программа для фитнес-центра30 Кб (XML) |
Разделение пользователей и схем
Схема — это коллекция объектов базы данных, имеющая одного владельца и формирующая одно пространство имен. (Две таблицы в одной и той же схеме не могут иметь одно и то же имя.) Компонент Database Engine поддерживает именованные схемы с использованием понятия принципала (principal). Как уже упоминалось, принципалом может быть индивидуальный принципал и групповой принципал.
Индивидуальный принципал представляет одного пользователя, например, в виде регистрационного имени или учетной записи пользователя Windows. Групповым принципалом может быть группа пользователей, например, роль или группа Windows. Принципалы владеют схемами, но владение схемой может быть с легкостью передано другому принципалу без изменения имени схемы.
Отделение пользователей базы данных от схем дает значительные преимущества, такие как:
-
один принципал может быть владельцем нескольких схем;
-
несколько индивидуальных принципалов могут владеть одной схемой посредством членства в ролях или группах Windows;
-
удаление пользователя базы данных не требует переименования объектов, содержащихся в схеме этого пользователя.
Каждая база данных имеет схему по умолчанию, которая используется для определения имен объектов, ссылки на которые делаются без указания их полных уточненных имен. В схеме по умолчанию указывается первая схема, в которой сервер базы данных будет выполнять поиск для разрешения имен объектов. Для настройки и изменения схемы по умолчанию применяется параметр DEFAULT_SCHEMA инструкции CREATE USER или ALTER USER. Если схема по умолчанию DEFAULT_SCHEMA не определена, в качестве схемы по умолчанию пользователю базы данных назначается схема dbo.
Заключительные замечания об агрегатноориентированных базах данных
Мы рассмотрели достаточно много материала, чтобы сделать краткий обзор трех разных стилей агрегатно-ориентированных моделей и их отличий.
Для всех них характерно понятие агрегата, индексированного ключом, который можно использовать для поиска. Агрегат очень важен для работы на кластерах, поскольку база данных в этом случае будет гарантировать, что все данные одного агрегата хранятся на одном узле. Кроме того, агрегат является атомарной единицей модификации, обеспечивая полезный, хотя и ограниченный объем управления транзакциями.
Агрегаты бывают разными. Модели данных типа “ключ—значение” интерпретируют агрегаты как “черный ящик”, т.е. искать можно только целые агрегаты, — вы не можете подать запрос на извлечение части агрегата.
В документной модели агрегат является прозрачным для базы данных. Это позволяет посылать запросы к фрагментам агрегата и осуществлять частичное извлечение данных. Однако, поскольку документ не имеет схемы, база данных не может сильно влиять на структуру документа, чтобы оптимизировать хранение и извлечение частей агрегата.
Модели типа “семейство столбцов” разделяют агрегат на группы столбцов, интерпретируя их как единицы данных в агрегате-строке. Это накладывает на агрегат структурные ограничения, но позволяет базе данных использовать эту структуру для улучшения доступа.
Преимущества графовых баз данных
Несмотря на то что практически все можно представить в виде графа, мы живем в прагматичном мире бюджетов, проектов с жесткими графиками, корпоративных стандартов и коммерческих правил. Предоставляемый графовыми базами данных новый мощный метод моделирования данных сам по себе не является достаточным основанием для замены устоявшихся и понятных платформ обработки данных — от этого должна быть незамедлительная и весьма значительная практическая польза. Для графовых баз данных такой мотивацией может послужить применение ее в тех случаях и к таким моделям данных, когда при переходе на графовую модель будет достигнуто увеличение производительности на один и более порядков. Вместе с выигрышем в производительности графовые базы данных предоставляют чрезвычайно гибкую модель данных и способ развертывания, соответствующий современным способам развертывания программного обеспечения.
Производительность
Одной из веских причин выбора графовой базы данных является большой прирост производительности при работе со взаимосвязанными данными, по сравнению с реляционными базами данных и NOSQL-хранилищами. В отличие от реляционных баз данных, где учет взаимосвязей интенсивно ухудшает производительность запросов на больших наборах данных, производительность графовых баз данных остается неизменной с увеличением объема хранимых данных. Это связано с тем, что запросы локализуются в определенной части графа. В результате время выполнения каждого запроса зависит от размера части графа, которую требуется обойти для удовлетворения запроса, а не от общего размера графа.
Гибкость
Разработчикам и проектировщикам необходимо организовать взаимосвязи между данными, согласно требованиям области применения, структура данных должна соответствовать изменяющимся потребностям, а не навязываться заранее и оставаться неизменной. В графовых базах данных эта задача легко решается. Как мы увидим в главе 3, графовая модель данных отражает и охватывает потребности бизнеса таким образом, что может изменяться со скоростью изменения самого бизнеса.
Присущая графам возможность расширения означает, что можно добавлять новые виды взаимосвязей, новые узлы, новые метки и новые подграфы в существующую структуру, не нарушив при этом существующих запросов и функционала приложения. Это положительно влияет на производительность разработки и снижает риски для проекта. Благодаря гибкости графовой модели не требуется предварительно моделировать задачу в мельчайших подробностях, что очень неудобно из-за быстро меняющихся бизнес-требований. Способность графов к расширению также позволяет уменьшить количество миграций, что снижает нагрузку при обслуживании данных и уменьшает риск потери данных.
Оперативность
Модель данных должна не отставать от прочих составных частей приложения и использовать технологии, соответствующие современным итерационным методам развертывания программного обеспечения. Современные графовые базы данных оснащены всем необходимым для разработки и системного обслуживания. В частности, встроенная графовая модель данных, лишенная схем, в сочетании со встроенным программным интерфейсом (API) и языком запросов позволяет эффективно вести разработку приложений.
В то же время благодаря отсутствию схемы графовые базы данных не предполагают наличия ориентированных на схемы механизмов контроля данных, которые широко применяются в реляционном мире. Но в этом нет ничего страшного, здесь они заменены гораздо более удобными и действенными видами контроля. Как мы увидим в главе 4, контроль выполняется в программной форме, с помощью тестов для моделей данных и запросов, а также с помощью определения бизнесправил, основанных на графе. Сейчас такая методика уже не вызывает сомнений: разработка с помощью графовых баз данных полностью соответствует современным методикам гибкой и надежной разработки программного обеспечения, что позволяет разработке приложений с использованием графовых баз данных не отставать от бизнес-среды.
Механизмы вычисления графов
Механизмы вычисления графов позволяют выполнять глобальные графовые вычислительные алгоритмы для больших наборов данных. Они предназначены для решения таких задач, как идентификация кластеров данных или получение ответов на такие вопросы, как: «Сколько всего взаимосвязей, сколько их в среднем, полна ли социальная сеть?»
Из-за своей направленности на глобальные запросы механизмы вычисления графов, как правило, оптимизированы для сканирования и пакетной обработки больших объемов информации, и в этом отношении они похожи на другие технологии пакетного анализа, такие как интеллектуальный анализ данных (data mining) или аналитическая обработка в реальном времени (OLAP), используемые в реляционном мире. Некоторые механизмы вычисления включают в себя и средства хранения графов, а другие (большинство) заботятся только об обработке данных, получаемых из внешнего источника, а затем возвращают результаты для сохранения в другом месте.
Рисунок 2 иллюстрирует типовую архитектуру развертывания механизмов вычисления графов. Она включает в себя систему записи (System of Record, SOR) базы данных со свойствами OLTP (например, MySQL, Oracle или Neo4j), которая обслуживает запросы и отвечает на запросы, поступающие от приложений (и в конечном счете от пользователей). Периодически задания на извлечение, преобразование и загрузку данных (Extract, Transform, Load, ETL) перемещают данные из системы записи базы данных в механизм вычисления графов для выполнения автономных запросов и анализа.
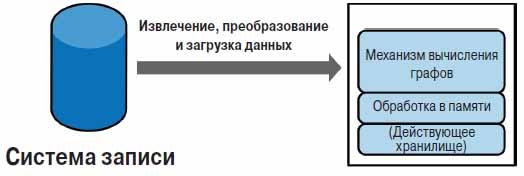
Рис. 2. Укрупненная схема типичной среды движков расчетов графов
Существуют разные типы механизмов вычисления графов. Наиболее известными из них являются одномашинные (in-memory/single machin), такие как Cassovary, и распределенные, такие как Pegasus и Giraph. В основе большинства распределенных механизмов вычисления графов лежит идея, изложенная в статье «Pregel: a system for large-scale graph processing», опубликованной на сайте Google, которая описывает движок Google для классификации страниц.
Базы данных и организация веб-ресурса
Каждый сайт состоит из HTML-страниц. На них есть определенный каркас — то, что одинаково на любой странице. И есть контент — на каждой странице он разный.
Раньше интернет-сайты создавали на чистом HTML, и это было неудобно, так как все данные были представлены как отдельные HTML-файлы. Нельзя было осуществлять поиск, группировку, сортировку информации. К тому же, информация могла часто дублироваться. При появлении PHP у веб-мастеров появилась возможность разделения сайта на его каркас и данные в базе. Теперь структуру сайта можно хранить отдельно от контента, что позволяет быстрее и удобнее администрировать веб-ресурс, легко дорабатывать его дизайн и функционал.
Структура веб-ресурса хранится в коде или в отдельных шаблонах (специальных файлах). Контент размещается в базе данных — определенном наборе таблиц с однотипными данными.
Допустим, мы создаем обычный сайт-визитку. У нас будет отдельная структура веб-сайта и база данных. В базе будут представлены несколько таблиц: 1 — с содержимым страниц, 2 — с новостной лентой, 3 — с фотогалереей.
Преимущества использования базы банных
- Быстрое управление посредством СУБД. Любая система управления БД работает на языке запросов SQL. К примеру, для сортировки данных достаточно указать всего лишь один параметр в SQL-запросе.
- Четкое структурирование и организация логики. К примеру, можно сделать выборку и точно узнать, сколько фото размещены в альбоме “Наше производство”. Или на сайте театра можно точно узнать, в каких спектаклях работает один катер.
- С применением БД легко решаются такие вопросы как поиск, сортировка, пагинация (разбиение на материалов постранично), работа пользователей в личном кабинете.
Итоги
В этой главе мы рассмотрели графовую модель со свойствами, представляющую собой простой, но удобный инструмент для работы со взаимосвязанными данными. Графовая модель со свойствами хорошо моделирует области ее применения, а графовые базы данных облегчают разработку приложений, которые реализуют графовые модели.
В следующем моем блоге мы сравним несколько различных технологий обработки взаимосвязанных данных, начнем с реляционных баз данных, затем перейдем к агрегированным NOSQL-хранилищам и закончим графовыми базами данных. Обсудив их, мы узнаем, почему графы и графовые базы данных являются лучшим средством для моделирования, хранения и выборки взаимосвязанных данных. Затем, в последующих главах, будут описаны проектирование и реализация решений, основывающихся на графовых базах данных.
Вас заинтересует / Intresting for you:
Что такое базы данных? Назначе… 1876 просмотров Ирина Светлова Mon, 28 Oct 2019, 05:41:34
Модели данных и языки запросов 493 просмотров Дэн Wed, 06 Mar 2019, 16:11:35
Хранение сложных структур данн… 581 просмотров Денис Thu, 28 Mar 2019, 14:52:48
Первичные и прочие ключи в баз… 7143 просмотров MashaSvetlova Sun, 09 Sep 2018, 11:32:06
Author: Aida
Другие статьи автора: