Распознавание текста с помощью решений abbyy
Содержание:
Onlineocr.net
Поиск по картинке в Гугл (Google) Как правильно пользоваться сервисом? +Отзывы

№7. Onlineocr.net
Простой и ненавязчивый, но в то же время вполне современный дизайн этого сайта делает работу с ним весьма приятной. А вот с характеристиками дела обстоят не очень хорошо. Сервис поддерживает крайне малое количество форматов изображений.
А форматов для сохранения готового текста и вовсе всего три штуки. Зато сервис совершенно бесплатен и работает с довольно высокой скоростью. Не радует только максимальный размер загружаемого файла – всего 15 Мб. Придется повторять процедуру много раз.
Преимущества:
- превосходный дизайн без лишних элементов
- очень высокая скорость работы
- простота в использовании
- русский язык в интерфейсе
- используется защищенное соединение
- присутствует мощный алгоритм распознавания
- отличная оптимизация сайта
Недостатки:
- очень мало поддерживаемых текстовых форматов (3)
- не хватает некоторых языков распознавания
- смешной лимит на максимальный размер загружаемого файла
OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы. Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой. Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из: 1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью; 2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией; 3) извлечение изображений размеченных символов на основе этого соотнесения; 4) выбор из размеченных символов подходящих обучающих примеров.Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
Как обойти OCR в антиплагиате?
Использование преподавателями при проверке студенческих работ функции OCR действительно осложнило ситуацию, особенно если она используется в совокупности с множеством дополнительных модулей поиска.
Старые методы искусственного завышения с появлением модуля OCR уже не действуют. Благодаря тому, что функция распознавания позволяет работать не с текстом как таковым, а с его видимым изображением, то замена букв и прочие устаревшие методы повышения уникальности никак не повлияют на процент в антиплагиате, а только обеспечат вам пометку «подозрительный документ», что наверняка не обрадует вашего научного руководителя. Однако обойти OCR все же возможно.
Самым действенным и честным способом остается самостоятельное написание работы. Так вы можете быть уверены, что успешно пройдете любые проверки на антиплагиате и получите отличную оценку. Конечно, далеко немногие студенты могут позволить себе самостоятельно писать курсовую или диплом вввиду своей загруженности, а написание качественного и оригинального материала требует много времени и сил.
Глубокий, основательный рерайт – это еще один способ значительно повысить уровень оригинальности работы. Воспользовавшись данным методом, вы получите совершенно новый текст. Несмотря на очевидные плюсы, глубокий рерайт занимает очень много времени и совершенно не подходит для ситуаций, когда действовать приходится в сжатые сроки.
Сервис ПОВЫСИТЬ-АНТИПЛАГИАТ.РФ поможет вам добиться высокого процента уникальности даже при проверке с включенным модулем OCR. Обработка документа занимает не более 2 минут, текст внешне не меняется. Стоимость услуги — 100 рублей за файл с любым количеством страниц.
История графологии
Графология — это древнейшее искусство. Несколько тысяч лет назад китайцы определяли по почерку характер человека, специалисты в древнем Риме, а позднее, монахи средневековья также владели этим искусством.
Примерно через 200 лет к теме почерка вернулись во Франции, когда ученый церковник аббат Фландрен заинтересовался книгой Бальдо. Аббат решил, что она заслуживает серьезного анализа и обсуждения. Он создал группу, участники которой занялись вопросом и подвергли классификации почерки людей, отличающихся друг от друга по интересам и роду занятий.
Участники исследования выработали правила, которые легли в основу современного анализа почерков. Для того, чтобы окрестить новую науку аббат использовал да греческих слова «графо» — писать и «ологи» — наука. Так родилась графология.
Ученик Фландрена Мишон более интенсивно развил графологические исследования и превзошел своего учителя. В 1872 году он написал книгу «Система графологии». Около 1880 года работа Мишона получила дальнейшее развитие в исследованиях Крепье-Жамена, в которых были применены более четкие методы классификации различных черт характера, которые выявил анализ почерка.
Графологией заинтересовались в Германии, затем в Англии, где многие интеллектуалы посвятили много времени совершенствованию анализа почерка. Графологами-любителями были премьер-министр Англии Дизраэли и американский писатель Эдгар Аллен По.
В конце XIX — начале XX столетия о графологии заговорили как о науке, а не как об искусстве. В начале XX века Людвиг Клагес (Германия) предпринял кропотливую работу по определению и обоснованию принципов графологии, методов ее применения и ее интерпретации. Современные исследователи почерка считают доктора Клагеса отцом современной графологии.
Существовало и Русское научное графологическое общество, председателем научной комиссии которого в 20-е годы был Д.М. Зуев-Инсаров, автор популярной книги «Почерк и личность». Однако в 1940 году профессор Познышев С. В. провел специальное исследование, в результате которого не усмотрел в графологии научных основ. На ней, несмотря на доброжелательное отношение многих видных людей, был поставлен крест. Впрочем, в те годы такая же печальная судьба постигла и некоторые другие науки, в полезности которых сегодня никто не сомневается.
С XIX века в различных странах возникли графологические общества
В Европе графология рассматривается с должным вниманием и занимает достойное место в работе психолога и психиатра. Она включена в учебные программы по психологии в университетах многих европейских стран
В Соединенных Штатах графология является еще сравнительно юной наукой. Ее основоположниками в этой стране явились Луи Райс и де Уитт Б. Лукас, книги которых по графологии стали первыми публикациями по этому предмету в США. Графологии стали обучать на очных и заочных курсах, а затем включать этот предмет в учебные программы.
Современные методы исследования почерка
В наши дни графологи работают повсеместно в штате многих крупных компаний. Их помощь необходима при приеме людей на работу. Известный психолог Карл Юнг первым отметил значение почерка человека при определении его характера и личных качеств.
Многие университеты США, Франции, Германии и Израиля включают графологию в курсы психологии и криминалистики. Обширные исследования в этой области, сделанные в XIX и XX веках преимущественно немецкими и французскими графологами, дали основу для работ современных аналитиков.
Отношение к графологии сегодня, как видим, вполне серьезное. Дело в том, что у нее есть кое-какие полезные результаты, которые трудно отрицать. Не надо быть графологом, чтобы в большинстве случаев безошибочно отличить мужской почерк от женского, детский от взрослого. Известно и то, что почерк — это слепок личности человека. Для доказательства ученые использовали гипноз.
Таким образом, одним из самых новых и самых важных направлении в исследовании почерка стало использование образцов письма пациента, полученных под гипнозом. Когда взрослые люди были подвергнуты гипнозу и им было внушено, что они — в детском возрасте, их почерк менялся, и они начинали писать как дети.
Эти эксперименты открывают новые возможности для графологов. Благодаря тому, что становится возможным анализировать почерк человека в различном возрасте, можно проследить развитие человека (интеллектуальное и эмоциональное) от детского до взрослого состояния.
SimpleOCR
Отличная небольшая программа для распознавания текстов с изображений. Поддерживает даже чтение рукописей.
Беда в том, что русский не входит ни в языковой пакет интерфейса, ни в список поддерживаемых для распознавания языков.
Однако если необходимо отсканировать английский, датский или французский, то лучшего бесплатного варианта не найти.
В своей области программа обеспечивает точную расшифровку шрифтов, удаление шума и извлечение графических изображений.
К тому же в интерфейс программы встроен текстовый редактор, практически идентичный WordPad, что значительно повышает удобство использования программы.
Достоинства:
- точное распознавание текста;
- удобный текстовый редактор;
- удаление шума с изображения.
Недостатки:
полное отсутствие русского языка.
Программа FineReader
Файн ридер — это программа по оцифровке документов, разработанная компанией ABBYY. Какие услуги предоставляет компания:
- Распознавание в онлайн-режиме. При помощи официальной страницы пользователям доступны преобразования сканов и PDF -форматов в текстовые варианты.
- Сканер текста при помощи мобильного приложения. Компания предоставляет программу и для мобильных устройств, с помощью которой можно преобразовать файл в текстовый документ.
- Компьютерная программа. С её помощью пользователь может просматривать, редактировать, комментировать документы.
Быстрым способом является оптическое распознавание текста онлайн. Это первый вариант, который предоставляется на сайте. Как это работает:
- На первом этапе нужно загрузить файл. Система принимает отсканированные форматы, фотодокументы в формате PDF. Необходимо отметить те страницы, которые будут обработаны.
- На втором этапе выбирается язык распознавания текста.
- На третьем этапе выбирается формат сохранения результата. На сайте можно выбрать любой текстовый формат.
- На четвёртом этапе необходимо сделать распознавание. Можно объединить страницы документа в один файл.
- На пятом этапе система предоставит файл для скачивания. Есть возможность отправить документы на различные интернет-диски.
Система может распознавать текст не более 100 МБ. Можно загружать несколько файлов одновременно.
Основные возможности:
- Преобразование бумажных документов в текстовые форматы.
- Обработка сканов и фотографий на более чем 190 языках.
- Отправка документов на интернет-диск для хранения в течение 14 дней.
- Возможность скачивания программ для мобильных устройств и компьютера.
Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
 Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Как пользоваться
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»
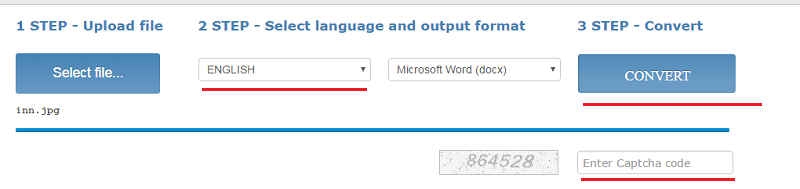
Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера
- Выберите область сканирования (можно оставить целиком как есть)
- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
- Внизу появится окно с текстом
OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Как пользоваться
-
-
- Загрузите файл, выберите язык и щелкните кнопку «Process»
-
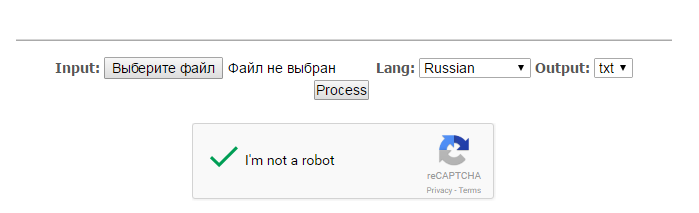
-
-
- Появится ссылка на файл с распознанным текстом
-

Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
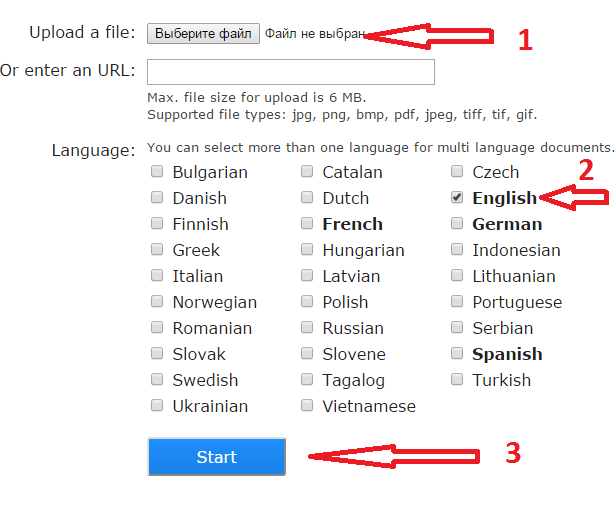
Как пользоваться
-
-
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”
-
I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert.
Замечено, что сервис временами не работает. |
Как пользоваться
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате