Работа с текстовыми файлами
Содержание:
feof
Функция
возвращает истину, если конец файла достигнут. Функцию удобно использовать, когда необходимо пройти весь файл от начала до конца.
Пусть есть файл с текстовым содержимым text.txt. Считаем посимвольно файл и выведем на экран.
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
void main() {
FILE *input = NULL;
char c;
input = fopen("D:/c/text.txt", "rt");
if (input == NULL) {
printf("Error opening file");
_getch();
exit(0);
}
while (!feof(input)) {
c = fgetc(input);
fprintf(stdout, "%c", c);
}
fclose(input);
_getch();
}
Всё бы ничего, только функция feof работает неправильно… Это связано с тем, что понятие «конец файла» не определено. При использовании feof
часто возникает ошибка, когда последние считанные данные выводятся два раза. Это связано с тем, что данные записывается в буфер ввода, последнее
считывание происходит с ошибкой и функция возвращает старое считанное значение.
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
void main() {
FILE *input = NULL;
char c;
input = fopen("D:/c/text.txt", "rt");
if (input == NULL) {
printf("Error opening file");
_getch();
exit(0);
}
while (!feof(input)) {
fscanf(input, "%c", &c);
fprintf(stdout, "%c", c);
}
fclose(input);
_getch();
}
Этот пример сработает с ошибкой (скорее всего) и выведет последний символ файла два раза.
Решение – не использовать feof. Например, хранить общее количество записей или использовать тот факт, что функции
fscanf и пр. обычно возвращают число верно считанных и сопоставленных значений.
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
void main() {
FILE *input = NULL;
char c;
input = fopen("D:/c/text.txt", "rt");
if (input == NULL) {
printf("Error opening file");
_getch();
exit(0);
}
while (fscanf(input, "%c", &c) == 1) {
fprintf(stdout, "%c", c);
}
fclose(input);
_getch();
}
Кодирование символов
Хотя стандарт допускает 8-битное кодирование в отдельных случаях, текст в формате RTF обычно кодируется 7-битными символами. Это ограничило бы нас набором символов ASCII, но остальные символы можно кодировать с помощью escape-последовательностей. Символы могут кодироваться двумя способами: кодами в рамках указанной кодировки символов либо кодами в Юникоде. Например, если задана кодировка Windows-1251, то код соответствует букве . Если требуется символ в Юникоде, используется код , сразу после которого указывается 16-битное число со знаком в десятичной системе счисления (значения, большие 32767, представляются как отрицательные), а за ним — символ для представления в программах, не имеющих поддержки Юникода. Например, арабская буква «ب» представляется в виде последовательности , причём в не-юникодных программах на месте этого символа выведется «?».
Автоматическое форматирование таблицы
Готовое оформление для существующей таблицы выбирают с помощью средства Автоформат. Варианты автоматического форматирования таблицы обычно обеспечивают различное оформление для разных элементов таблицы, например для заголовков строк и столбцов или для итоговых данных.
Выбор формата таблицы
- Выделите форматируемый диапазон.
- Дайте команду Формат Автоформат — откроется диалоговое окно Автоформат. Если на первом этапе была выбрана только одна ячейка, программа определит форматируемую область автоматически.
- Выберите подходящий вариант оформления на панели с образцами.
- Для частичного применения параметров форматирования нажмите кнопку Параметры — в окне появится дополнительная панель Изменить.
- Сбросьте флажки панели Изменить, соответствующие параметрам, настройка которых не требуется.
- Выполните автоматическое форматирование таблицы кнопкой ОК.
Описание
Основная статья: текстовые данные
Текстовый файл содержит последовательность символов (в основном печатных знаков, принадлежащих тому или иному набору символов). Эти символы обычно сгруппированы в строки (англ. lines, rows). В современных системах строки разделяются разделителями строк, в прошлом же применялось хранение строк в виде записей постоянной или переменной длины (см.: Перфокарта). Иногда конец текстового файла (особенно если в файловой системе не хранится информация о размере файла) также отмечается одним или более специальными знаками, известными как маркеры конца файла.
Преимущества и недостатки
Преимущества:
- Универсальность — текстовый файл может быть прочитан (так или иначе) на любой системе или ОС, особенно если речь идёт об однобайтных кодировках вроде ASCII, которые не подвержены проблеме, характерной для других форматов файлов — для них не важна разница в порядке байтов или длине машинного слова на разных платформах.
- Устойчивость — каждое слово и символ в таком файле самодостаточны и, если случится повреждение байтов в таком файле, то обычно можно восстановить данные или продолжить обработку остального содержимого, в то время как у сжатых или двоичных файлов повреждение нескольких байтов может сделать файл совершенно невосстановимым. Многие системы управления версиями рассчитаны на текстовые файлы и с двоичными файлами могут работать только как с единым целым.
- Формат текстового файла крайне прост и его можно изменять текстовым редактором — программой, входящей в комплект практически любой ОС.
Недостатки:
- У больших несжатых текстовых файлов низкая информационная энтропия — эти файлы занимают больше места, нежели минимально необходимо. Хотя эта избыточность и определяет повышенную устойчивость к сбоям в каналах передачи данных и при получении данных с носителей, например, с магнитной ленты.
- Некоторые операции с текстовыми файлами неэффективны. Например, если в файле встретится число, вычислительная система до начала операций с ним должна будет перевести его в свой внутренний формат, применив сравнительно сложную процедуру конвертации числа; чтобы перейти на 1000-ю строку, требуется считать 999 строк, идущих до неё; сложно заменить одну строку другой и т. д. Поэтому при работе с большими объёмами данных текстовые файлы применяют только как промежуточный формат, обеспечивающий интероперабельность.
Форматы, основанные на текстовых файлах
В силу своей простоты текстовые файлы нередко используются для хранения служебной информации (например, логов): так как операция добавления в конец текстового файла новых данных не требует сколь-нибудь значительных вычислительных ресурсов независимо от уже имеющегося объёма файла и вида добавляемых текстовых данных, ведение текстовых лог-файлов обычно происходит эффективно и незаметно для пользователя и для других приложений (вплоть до исчерпания дискового пространства).
Текстовый формат служит основой для многих более специализированных форматов (например, .ini, SGML, HTML, XML, TeX, исходных текстов языков программирования). В некоторых из таких форматов определённые сочетания символов могут использоваться как средства разметки текста. В таком случае файл может хранить форматированный текст, в котором для символов дополнительно может быть задан шрифт, начертание, размер и т. п. (например, Rich Text Format, HTML).
Расширения имён файлов
В DOS,Mac os и Windows для файлов с неформатированным текстом обычно используется расширение .txt. Тем не менее, текстовыми могут являться файлы с любым другим расширением или без оного. Например, исходные коды программ обычно хранятся в файлах с расширениями, соответствующими языку программирования, на котором написаны программы (.java, .bas, .pas, .c).
Форматированный текст (текст с разметкой) обычно хранится в файлах с расширением, соответствующим формату или языку разметки — .rtf, .htm, .html.
Выравнивание текста
Существует 2 типа выравнивания:
1. Горизонтальное выравнивание
Применяется с помощью выбора одной из команд, расположенных меню Формат:
Выравнивание текста в Apple Pages
Текст можно выровнять:
- По левому краю — ровный край слева;
- По центру — относительно центра листа;
- По правому краю — ровный край справа;
- По ширине — оба края ровные.
2. Вертикальное выравнивание
Включает в себя межстрочный интервал и интервалы до и после фрагмента текста.
Межстрочный интервал применяется с помощью раздела Интервалы, расположенного в меню Формат.
Изменение интервалов до и после текста доступно если развернуть пункт Интервалы.
Быстрое форматирование
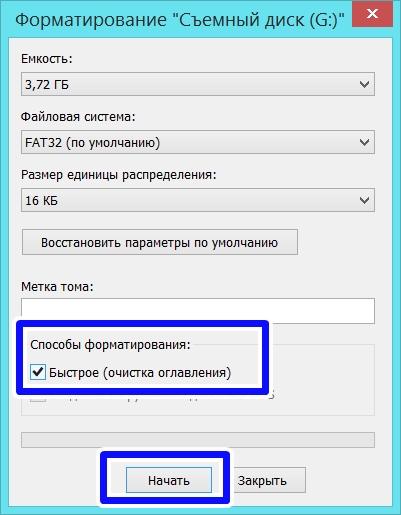 Большинство пользователей зачастую выбирают быстрый способ, потому что он позволяет избавиться от всех данных на устройстве за пару минут. Но так ли это?
Большинство пользователей зачастую выбирают быстрый способ, потому что он позволяет избавиться от всех данных на устройстве за пару минут. Но так ли это?
Альтернативное название этого вида форматирования — очистка оглавления. Это значит, что вы лишь упорядочиваете оглавление, которое содержит сведения о записанных файлах, а сами данные остаются.
Вы можете возразить, мол, в таком случае не было бы свободного места для записи другой информации.
Да, вы действительно освобождаете пространство на диске. Но происходит это за счет перезаписи таблицы файловой системы.
Память накопителя помечается как неиспользуемая, поэтому вы и компьютер видите его пустым. Однако область данных при таком форматировании не затрагивается, из-за чего они могут быть при желании восстановлены.
Какое форматирование выбрать?
Полная чистка, конечно, эффективнее простой. Она актуальна в таких случаях:
- Вы отдаете накопитель чужому человеку и боитесь, чтобы он может восстановить вашу старую информацию;
- На устройство попали вирусы;
- Происходят частые сбои, последующая запись информации ведется с ошибками, что вызывает подозрения о наличии битых секторов.
Однако не всегда есть время на полное форматирование. Когда речь идет о диске на 40 Гб, то еще куда ни шло, но в случае с жестким диском в терабайт — можно успеть и поспать. Кстати, так обычно и происходит: если нужно очистить HDD, то лучше запускать процесс на ночь :).
Быстрое форматирование не так уж плохо, как может показаться. Более того, в большинстве ситуаций именно этот вариант предпочтительнее. Например, когда нужно срочно удалить файлы с флешки и записать новые. Также его вполне достаточно при очистке системного диска перед переустановкой Windows.
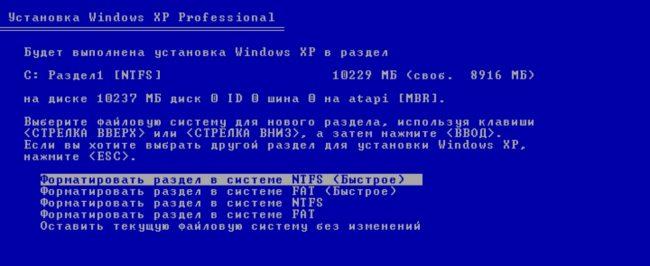
Это всё, что касается того, чем отличается быстрое форматирование от полного. Подписывайтесь на обновления моего блога, чтобы не пропускать интересную информацию.
До свидания.