Abbyy finereader 14 на русском бесплатно
Содержание:
- Readiris
- Параметры сканирования текста
- Как распознается текст
- Распознать и перевести текст
- Преимущества использования специальных программ
- Редактируйте любые PDF-файлы легко и быстро
- А как правильно сфотографировать документ с помощью приложения Google Диск на смартфоне Samsung?
- Fine Scanner – программа для распознавания текста для iPhone
- Локализация
- RiDoc
- Распознавание формата PDF и графических файлов на сервере
- Abbyy Fine Reader
- Возможности ABBYY FineReader
- PDFelement Pro
- Выбор
Readiris
Readiris — утилита для распознавания и сканирования документов. С помощью приложения можно распознать текст с изображения и сохранить итоговый результат в любом удобном формате: PDF, Word, Excel, XPS. Программа работает с более 100 языков. Есть возможность отправки документов в облачное хранилище: Dropbox, Google Drive, OneDrive, Evernote и т.д.
Утилита полностью совместима с операционной системой Windows (32 и 64 бит). Для комфортной работы требуется Windows 7 и новее. На официальном сайте разработчиков доступна полностью русская версия для скачивания. Модель распространения приложения для распознавания текста Readiris — платная. Чтобы пользоваться всеми возможностями программы, необходимо купить лицензию. Стоимость базовой версии составляет 49 евро. Цена Pro-версии — 99 евро.
Преимущества Readiris Pro перед базовой версией:
- Обработка документов на 20% быстрее.
- Утилита распознает 138 языков (в базовой версии — 30).
- Наличие функции для установки защиты на PDF-документы.
- Конвертация файлов в формат для приложений от Microsoft: Word, Excel, PowerPoint.
Чтобы опробовать все функции программы, можно загрузить бесплатную Trial-версию. Срок действия ознакомительной версии — 10 дней. За это время можно преобразовать не более 150 страниц документации: текст, изображения, таблицы, презентации. После запуска утилиты откроется главное окно. Первый доступный раздел — «Главная».
Здесь пользователи могут сделать скан документа. Также в этом разделе расположен инструмент, который используется для распознавания текста. Перед началом работы нужно выбрать язык документа.
Следующий этап работы — это загрузка файла в программу. Поддерживается возможность пакетного распознавания документов. В случае с пакетной загрузкой файлов для распознавания текста необходимо выбрать папку, где расположены изображения и раздел, в который будет сохранен результат. Также пользователи могут выбрать выходной формат: формат, в котором файл будет экспортирован на компьютер.
После завершения рапознавания текста необходимо сохранить итоговый результат. На выбор доступно несколько форматов, которые определяются на верхней панели инструментов приложения Readiris.
Преимущества программы Readiris:
- простой и удобный интерфейс на русском языке;
- поддержка более 100 языков для распознавания;
- возможность корректирования текста перед сохранением.
Недостатки:
нельзя установить утилиту на Windows XP или серверные версии операционной системы.
Параметры сканирования текста
Здесь я не будут рассказывать о ваших драйверах для сканера, программах, которые вместе с ним шли, ибо все модели сканеров разные, ПО тоже везде разное и угадать и тем более показать наглядно как выполнять операцию — нереально.
Но во всех сканерах есть одни и те же настройки, которые сильно могут повлиять на скорость и качество вашей работы. Вот о них таки как раз и поговорим здесь. Буду перечислять по порядку.
1) Качество сканирования — DPI
Во-первых, качество сканирования поставьте в опциях не ниже 300 DPI. Желательно даже выставить побольше, если это возможно. Чем выше показатель DPI — тем четче получиться ваша картинка, ну и тем самым, быстрее пройдет дальнейшая обработка. К тому же чем выше качество сканирования — тем меньше ошибок вам в последствии придется исправлять.
Оптимальный вариант обеспечивает, обычно, 300-400 DPI.
2) Цветность
Этот параметр очень сильно влияет на время сканирования (кстати, DPI тоже влияет, но те так сильно, и только когда пользователь ставит высокие значения).
Обычно выделяют три режима:
— черно-белый (отлично подойдет для простого текста);
— серый ( подойдет для текста с таблицами и картинками);
— цветной (для цветных журналов, книг, в общем, документов, где важна цветность).
Обычно от выбора цветности зависит время сканирования. Ведь если документ у вас большой, то даже лишние 5-10 секунд на странице в целом выльются в приличное время…
3) Фотографии
Документ вы можете получить не только сканированием, но и сфотографировав его. Как правило, в этом случае у вас будут некоторые другие проблемы: искажение картинки, смазанность. Из-за этого может потребоваться более длительная дальнейшая правка и обработка полученного текста. Лично я не рекомендую пользоваться фотоаппаратами для этого дела.
Важно отметить, что не каждый такой документ получится распознать, т.к. качество сканирования у него может быть крайне низким..
Как распознается текст
Программа превращает графическое изображение в текстовый файл
Программы, считывающие текст с картинки или изображения страницы, оптически распознающие его, конвертируют сфотографированные или отсканированные документы в слова и предложения.
Графический формат превращается в текстовый файл.
Ведь на изображении каждая буква состоит из точек или пикселей, а средства OCR (Optical Character Recognition или оптического распознавания символов) воспринимают это.
Затем приводят изображения отдельных букв в соответствие с символами алфавита, сравнивая с базой элементов. В результате получается обычный текст с расширением, удобным для редактирования и сохранения.
Распознать и перевести текст
Пример перевода вы видите на скриншоте. Выделил текст, получил результат.
Скачивайте программу с сайта разработчиков Gres http://gres.biz/screen-translator/
Программа скачивается немного необычным образом.
1. Скачиваете установщик.
2. Выбираете необходимый пакет языков.
3. Установщик скачивает программу с выбранным комплектом и устанавливает на ПК.
Инструкция по установке
Под заголовком «Скачать» выбираете «Установщик».
Скачиваете один из файлов как показано на рисунке.
Запускаете установочный файл, далее всё, как обычно до момента выбора языков.
Выбрать можете все языки или только, которые необходимы. Это повлияет только на время загрузки и установку программы.
Я выбрал три языка
– русский;
– английский;
– китайский.
Процесс установки, в моём случае, занял минут 15.
Настройка программы
В общих настройках можно задать горячие клавиши или оставить по умолчанию. Это кому как удобно.
Прокси-сервер уже вряд ли кто использует, здесь ничего не меняем.
Вывод результата — здесь пробуйте, что больше понравиться.
Во вкладке «Распознавание» я поставил язык английский, так как в основном приходится использовать этот язык. При изменении параметра «Увеличение масштаба», я никаких изменений не заметил.
Последняя вкладка «Перевод». Здесь проставляете везде галочки и выбираете язык, на котором будете получать готовый результат.
Как работать с программой
Для захвата текста используйте горячие клавиши или мышь.
Если использовать мышь, то в трее находите программу кликаете правой мышкой и выбираете «Захват».
Курсором выделяете нужную область и ждёте результат.
Распознавание и перевод занимает некоторое время. Через несколько секунд программа, выдаст окно, в котором оригинал текста и ниже перевод. Показано на самом первом скриншоте.
Всю последнюю информацию можно скопировать в буфер обмена при помощи горячих клавиш и с использованием мыши.
Настройки сделаны, с работой разобрались. На самом деле работать с программой, которая может распознать и перевести текст несложно, а удобно, экономя при этом драгоценное время.
Расширение
Наряду с программой рекомендую использовать и расширение для браузера Гугл Хром, Copyfish Free OCR Software.
Работа с расширением происходит аналогично работе с программой описанной выше.
Распознавание и перевод происходит достаточно быстро.
Выделив нужный текст, получите результат в открывшемся новом окне.
В настройках можно выбрать:
– язык входа и выхода;
– быстрый выбор языка;
– размер шрифта в текстовом поле.
На этом всё. Думаю программа и расширение помогут вам распознать и перевести необходимый текст без потери времени, быстро и качественно.
Преимущества использования специальных программ
Программы читают рукописный текст
Главная проблема, которую решает распознавание рукописного ввода — экономия времени. На то, чтобы вручную перепечатать текст нужно потратить колоссальное количество времени, при этом эта работа быстро утомляет и надоедает. Компьютерные программы могут значительно облегчить такой рутинный труд. Учитывая это, есть смысл потратиться на покупку лицензионной программы, которая будет качественно сканировать документы
Это особенно важно для тех, у кого такая потребность возникает постоянно
Бесплатные программы подойдут тем, кому редко нужно сканировать документы. К примеру, если кто-то хочет отсканировать письма из семейного архива, он может воспользоваться бесплатными программами. С такой задачей они вполне справятся.
Алгоритмы платных программ работают быстрее и эффективней, они поддерживают больше языков и стилей написания. Также в платных версиях намного больше дополнительных возможностей.
Редактируйте любые PDF-файлы легко и быстро
PDFelement для Windows существенно упрощает редактирование PDF. Меняйте водяные знаки, изображения, тексты, ссылки, колонтитулы, фоны, разметку страниц и многое другое!
Текст
Используйте интуитивно понятные режимы абзаца и отдельной строки для удобного редактирования текста. Меняйте шрифт, стиль и размер по мере необходимости.
Изображения
Работайте с изображениями без усилий, добавляя, поворачивая, распаковывая, обрезая, вставляя, заменяя, копируя и удаляя картинки.
Страницы
Преобразуйте документы с легкостью. Извлекайте, обрезайте, заменяйте, вставляйте и разделяйте страницы, настраивайте поля или добавляйте разметку страниц.
А как правильно сфотографировать документ с помощью приложения Google Диск на смартфоне Samsung?
Далее мы покажем порядок фотографирования любого документа на примере редакционного смартфона Samsung Galaxy A50 с ОС Android 9 Pie.
Инструкция по фотографированию документов на смартфоне Samsung.
1. Заходим в папку на Главном экране смартфона.
Скрин №1 – открываем папку Google.
2. Запускаем приложение Диск.
Скрин №2 – запускаем приложение Google Диск.
3. Для начала сканирования нужно нажать на значок «+» в круге, расположенный внизу экрана справа.
Скрин №3 – нажимаем на значок «+» в круге.
4. В открывшемся меню «Новый объект» нажимаем на значок «Сканировать».
Скрин №4 – нажимаем на значок «Сканировать».
5. Программа запускает камеру смартфона. Вы наводите камеру на ваш документ так, чтобы он полностью вошёл в кадр, и нажимаете на кнопку «Съёмка».
Скрин №5 – сфотографировать документ, для этого нужно навести камеру на лист бумаги с текстом, и нажать на кнопку «Съёмка».
6. Тут же на экране появляется кадр отснятого текста, а внизу экрана — две кнопки «Повтор» и «ОК». Если качество кадра вас устраивает, тогда нажмите на кнопку «ОК».
Скрин №6 – нажимаем на кнопку «ОК».
7. На экране предварительный результат работы сканера: отсканированный документ с обрезанными «лишними» полями. Если качество сканирования вас не устраивает и программа отрезала «лишнего», тогда нужно перейти в режим кадрирования, а для этого нужно нажать на значок «Кадрирование».
Скрин №7 – нажимаем на значок «Кадрирование».
8. Теперь вы в режиме кадрирования. Здесь нужно установить «голубые» границы отсканированного документа строго по краю листа. Для этого нужно свайпом перемещать «голубые линии» до совпадения их с краем листа. После этого нужно нажать на значок «Галочка» внизу экрана.
Скрин №8 – перемещаем свайпом «голубые» границы под край листа. Скрин №9 – для сохранения настройки сканирования нажмите на значок «Галочка».
9. На экране отсканированный документ. С документом всё в порядке: весь текст на листе, сам он прямоугольной формы без перекосов и текст строго горизонтальный.
Его нужно сохранить. Для этого нужно нажать на значок «Галочка» внизу экрана.
Скрин №10 – для сохранения отсканированного документа нажмите на значок «Галочка».
На следующей странице «Сохранить на Диске» вы можете изменить название файла или выбрать иную папку для хранения в «облаке». После этого обязательно нужно нажать на кнопку «Сохранить».
Скрин №11 – для сохранения скана документа на Диске нажмите на значок «Сохранить».
10. Приложение сохранило отсканированный текст в облаке на сервере Google Диск. Здесь вы можете посмотреть его, скачать на свой смартфон, переслать по почте, или направить на его печать. Для этого в строчке файла отсканированного документа вам нужно нажать на значок «Трёхточье», и вам откроется меню для работы с этим файлом.
Скрин №12 – для работы с файлом нажмите на значок «Трёхточье». Скрин №13 – вид меню для работы с файлом.
Fine Scanner – программа для распознавания текста для iPhone
- Скачать Fine Scanner.
- Разработчик: ABBYY.
- Оценка: 5,0.
Fine Scanner – приложение от ABBYY. На десктопе в начале века компания считалась лидером в области сканирования и перевода документов. Сегодня у нее уже немало конкурентов. Однако технологии остались и можно ожидать хорошего качества сканирования текста.
Fine Scanner умеет автоматически захватывать текст на странице при съемке камерой. Есть режим сканирования книги, а также «лучший из трех», который может пригодиться при недостатке освещения.
Скан документа можно подправить с помощью фильтров, например, сделать более контрастным. Также после съемки можно повернуть скан, обрезать его.
Распознавание текста происходит в облаке. Поддерживается его автоматический экспорт в нужный формат, в том числе DOCX, который потом можно отправить любым удобным способом.
Приложение условно бесплатное и предоставляет возможность бесплатно обработать только пять документов.
Локализация
Это нахождение документа на изображении. Для локализации мы пробовали три основных подхода:
- OpenCV и обученный классификатор Хаара
- Полносверточные нейронные сети
- Аналитический подход на основе поиска связных компонент
В первом подходе документ помечается прямоугольником и обрезается до тех пор, пока в рамке не останется выделенной область с текстом; если документ на видео не найден, то алгоритм продолжает поиск в видеопотоке.
Во втором подходе мы применяем полносверточные нейронные сети. На вход сети подается цветное изображение паспорта. На выходе формируется два канала: первый используется для поиска центра первой страницы паспорта, второй — для поиска центра второй страницы. При этом сеть тренируется предсказывать маску, в которой над центрами страниц паспорта находятся гауссовы пики.
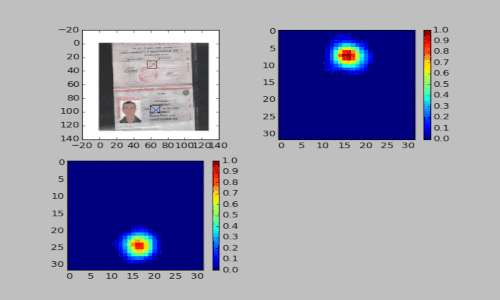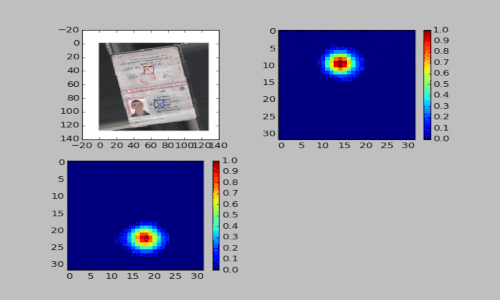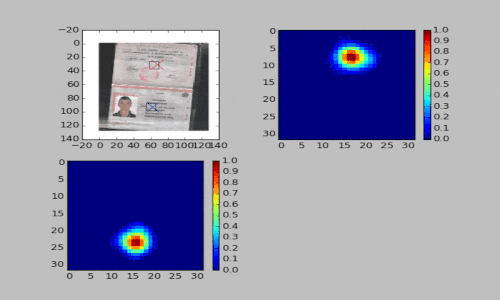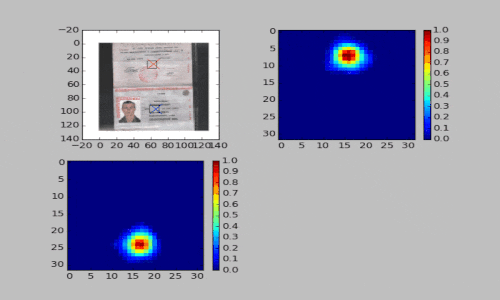
Третий подход мы применили для распознавания паспорта. Использовали шаблон, где на развороте паспорта находились две области с серией и номером документа. Если такой шаблон в кадре, то перед нами паспорт. В основе данного подхода лежит поиск связанных компонент. Смотрите видео ниже.
RiDoc
RiDoc — специальная утилита для сканирования документов и распознавания текста. Итоговый результат можно сохранить в любом удобном формате: jpeg, tiff, bmp, png. Есть возможность экспорта файлов в PDF и Microsoft Word. Поддерживается функция склейки несколько документов. На склеенный файл можно наложить водяной знак.
Приложение полностью совместимо с операционной системой Windows (на 32-х и 64-битных версиях). Для установки и запуска утилиты требуется Windows XP и новее. Доступна полностью русская версия для скачивания. Модель распространения программы RiDoc — условно-бесплатная. Чтобы получить полную версию приложения, необходимо купить лицензию. Стоимость лицензионной версии для личного использования составляет 350 рублей. Доступна бесплатная пробная версия на 30 дней. На сохраненных документах будет размещена надпись «No registration».
Чтобы начать работу с утилитой, необходимо запустить RiDoc на компьютере. На первом этапе нужно загрузить изображение или PDF-файл для распознавания текста. Для этого используется функция «Открыть», которая расположена на панели инструментов. После того, как файл загружен в программу, пользователи могут приступать к процессу распознавания текста. Для этого необходимо нажать кнопку «Распознать» на панели инструментов.
Время выполнения этой задачи зависит от общей длины текста на изображении. Итоговый результат отобразится в отдельном окне в правой части интерфейса программы RiDoc.
Пользователи могут скопировать этот текст, внести собственные изменения или добавить новые текстовые блоки. Также результат можно сохранить на компьютер. Для этого необходимо воспользоваться функциями, которые расположены на верхней панели инструментов.
Файл можно сохранить в формате картинки, MS Word, OpenOffice или PDF. Также доступна функция отправки документа по электронной почте. Есть инструмент для печати файла на отдельном листе бумаги любого размера.
Преимущества программы RiDoc:
- простой и удобный интерфейс с поддержкой русского языка;
- быстрое распознавание текста;
- программа работает с графическими изображениями и документами формата PDF;
- итоговый результат распознавания текста можно отправить по электронной почте;
- доступна функция склейки несколько документов с возможностью добавления водяных знаков.
Недостатки:
нет интеграции с популярными облачными сервисами.
Распознавание формата PDF и графических файлов на сервере
Чтобы система могла распознавать графические и PDF файлы на сервере, потребуется:
- установить специальные утилиты CuneiForm, Ghostscript и ImageMagic;
- зайти в настройки программы и указать параметры распознавания и путь к ImageMagic.
Утилита CuneiForm позволяет системе распознавать графические файлы. Если используется файловый вариант системы 1С:Документооборот, надо указать того пользователя, который будет с ней работать. Если используется клиент-серверный вариант, следует указать пользователя, под чьим именем осуществляется работа сервиса 1С:Предприятие.
Утилита ImageMagic преобразовывает графические файлы в формат PDF и наоборот. Ghostscript является вспомогательной программой для ImageMagic и обеспечивает преобразование файлов. Обе программы устанавливаются на компьютер пользователя.
Abbyy Fine Reader
Программа для распознавания текста с картинки от разработчика ABBYY считается одной из лучших. В своем функционале имеет множество инструментов. В зависимости от версии она работает и с djvu-файлами.
Источник сканов
Сканирование. Перед началом работы с растровыми изображениями необходимо настроить сканер текста с фото. В настройках указывается максимальное количество точек на дюйм (DPI). Рекомендуемое значение не ниже DPI 300. Чем больше этот показатель, тем выше качество и меньше вероятность возникновения ошибок.
Цветность. От цветности зависит скорость сканирования. Среди основных ее настроек три варианта:
- Черно-белый — подходит для сплошного текста.
- Оттенками серого можно воспользоваться, если нужно сканировать документ, содержащий картинки, таблицы и текст.
- Цветным режимом пользуются, когда идет оцифровка журналов и периодики, для которых цветопередача важнее содержания.
Фотография. Программа для считывания текста с картинки работает не только со сканами, но и с фотографиями, снятыми на фотоаппарат или на смартфон в хорошем разрешении. Но как показывает практика, снимки со смартфона имеют искажения, которые влияют на распознавание.
Распознавание графических документов
Утилита работает почти со всеми популярными файлами с расширением jpeg, bmp, png, tiff. Рабочая область имеет два экрана. На левом находится исходник, на правом — результат. После загрузки фото в программу производится его распознавание, но не всегда процедура происходит корректно. Часто приходится прибегать к ручному режиму. Если есть выход в интернет, то полученный результат можно проверить на орфографические ошибки.
Текст. На панели инструментов есть иконка «Т», которая при выделении области исключает работу с таблицами и изображениями. При наличии на странице нескольких таблиц, выделять текст придется несколькими блоками. После чего нажимается иконка «Распознать».
Таблицы. Работа с таблицами сопряжена с некоторыми трудностями. Внутреннее содержание распознается и вставляется в Excel. Но если необходимо ту же таблицу разместить на странице Word, то ее придется создавать заново, а распознанные данные вставляются с ошибками.
Изображения. При необходимости копирования изображений со сканированного листа они просто выделяются, копируются и вставляются. Не нужно пользоваться графическим редактором для обрезки. Word обладает рядом инструментов для редактирования изображений.
Ненужные области. На отсканированных страницах встречаются области, мешающие работе, такие как реклама и колонтитулы. Перед работой с документами эти области следует удалить. В Fine Reader есть функция «ластик». С ее помощью ненужная область удаляется полностью до белого листа.
Работа с DJVU и PDF
Документы этих форматов не что иное, как графические изображения, преобразованные в формат меньшего объема. И хранить таких документов можно значительно больше на ограниченном объеме памяти.
Распознавание и чтение файлов djvu и pdf идет по всей странице, включая номера страниц и колонтитулы. Это затрудняет дальнейшее редактирование. Чтобы исключить лишнюю информацию в программе устанавливаются дополнительные настройки, ограничивающие рабочую область. Делается это следующим образом:
- Редактирование → работа с изображениями.
- Активировать опцию «Обрезка».
- Установить границы обработки.
- Сохранить настройки кнопкой «Применить ко всем страницам».
Возможности ABBYY FineReader
- Программа распознавания текста, предполагает работу со 179 языками;
- После обработки текста, имеется опция его сохранения, а также отправка по почте или публикация в интернет-сети;
- Встроенные инструменты, отвечающие за увеличение качества фото и изображений;
- Точность распознания пдф, сканов и изображений благодаря технологии Abbyy OCR;
- Утилита поддерживает Windows 7, а также Windows 8 и 10;
- Возможность конвертирования готового текста в форматы PDF, DOC, RTF, XLS и HTML;
- Сохраняется оформление, а также стиль документа с последующей возможностью запуска через Microsoft Word, Outlook и Excel;
- Программа поддерживает распознавание документов, полученных с МФУ, сканеров, цифровых фотоаппаратов и даже с мобильного телефона;
- Имеется русская версия реализации простого и понятного интерфейса;
- Зарегистрированным пользователям лицензионного Абби Файнридер предоставляются доступ к онлайн сервису Abbyy Finereader Online.
Преимущества
- Разработчик ABBYY, предоставляет периодические обновления своей утилиты сканирования, распознавания текста;
- Обработка документов, которые были сфотографированы на мобильное устройство;
- Одновременная работа с пакетом изображений или сканов;
- Наличие полезных дополнений, таких как ABBYY Screenshot Reader и прочие;
- Программное обеспечение автоматически распознает разные языки в одном документе;
- Высокие показатели точности оптического распознавания текстовой информации;
- Сохранение исходного высокого качества изображения документов;
- Поддерживается любая актуальная система Windows, отличные показатели работы с редакторами Microsoft Office;
- Программа распознавания текстовых данных, сохраняет контент в редактируемый формат;
- Имеется профессиональная модификация софта FineReader 12;
- Приложение качественно обрабатывает персональные бумажные документы.
Недостатки
PDFelement Pro
Программа PDFelemnt PRO — комплексное решение задач по работе с PDF файлами. ПО может на равных конкурировать со своими аналогами. Здесь есть много функций, которые могут понадобиться при работе с текстом, в том числе — функция распознавания текста. У программы специфичный набор функций, которые не связаны с распознаванием текста.
Распознавание текстов
PDFelement PRO создан для работы работы с форматом PDF. Бесплатная версия программы позволяет редактировать, аннотировать, создавать, объединять и разделять PDF файлы. Распознавание текста доступно только в платной версии, но качество и результаты работы остаются на высоком уровне.
Дополнительные функции
С помощью программы можно делать документы конфиденциальными (ставить на файлы пароль), можно создавать готовые шаблоны, ставить штамы и т.д. В целом, программа подойдет больше тем, кто работает с PDF файлами. Хотя в ней и есть функция распознавания рукописного ввода, она здесь не является главной.
Выбор
Как же выбрать наиболее подходящую программу, и какие основные особенности имеет такой софт?
Отличаться он может по разным показателям – точности распознавания, способности работать с тем или иным языком, возможности сохранять исходную структуру текста и т. п.
Такой софт может распространяться платно и бесплатно, и быть реализован как онлайн (в виде особых сервисов), так и в форме предустанавливаемых программ.
Алгоритм работы заключается в том, что для каждой буквы алфавита составляется база вариантов того, как она может выглядеть на фото, выделяются и сохраняются ее основные элементы. Как только такие элементы обнаруживаются на фото, программа распознает соответствующую букву. В зависимости от того, насколько качественно и подробно была составлена такая база, зависит качество распознавания материала в итоге.
Потому важно, чтобы софт был рассчитан на работу именно с русским языком (некоторые программы могут работать с текстом, написанным сразу на двух языках, другие – нет). Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста (таблицы, списки), тип его оформления (отступы и т
п.) и даже шрифт
Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста (таблицы, списки), тип его оформления (отступы и т. п.) и даже шрифт.
В каких же случаях такой софт необходим?
- При создании документов, когда имеется только распечатанный вариант;
- При составлении рефератов, докладов и необходимости процитировать в них большой отрывок текста из книги;
- Для редакторских работ, когда текст имеется лишь в формате фото и т. д.
На самом деле сфера использования софта очень велика, и правильно выбранный, он способен облегчить и ускорить работу с текстом.